La prévision par des méthodes statistiques "classisques" et par Machine Learning
Les méthodes d’apprentissage automatique sont régulièrement mises en avant en tant que la solution adaptées à tous les problèmes de modélisation prédictive et peuvent surpasser les méthodes statistiques classiques.
Certaines études ont rapporté des résultats comparatifs différents. Nous présentons ci-après les résultats de deux études qui mettent en évidence des performances contrastées.
Etude où les méthodes statistiques "classiques" se sont avérées plus performantes
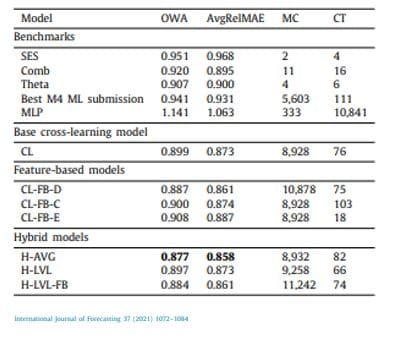
Dans une étude (Makridakis S. et al., 2018) évaluant et comparant les performances des méthodes « classiques » et d’apprentissage automatique sur un ensemble vaste et diversifié de plus de 1 000 ensembles de données de prévision de séries chronologiques univariées, et qui a utilisé une série par stratégie de modélisation en série, nous avons appris :
- Les méthodes classiques comme ETS et ARIMA surpassent les méthodes d’apprentissage automatique (Machine Learning) et d’apprentissage en profondeur (Deep Learning) pour la prévision en une étape sur des ensembles de données univariées (basées sur l’erreur absolue moyenne symétrique en pourcentage).
- Les méthodes classiques comme ARIMA surpassent les méthodes d’apprentissage automatique et d’apprentissage en profondeur pour la prévision en plusieurs étapes sur des ensembles de données univariées.
- Les méthodes d’apprentissage automatique et d’apprentissage en profondeur ne tiennent pas encore leurs promesses en matière de prévision de séries chronologiques univariées.
Etude où les méthodes d'apprentissage automatique ont été jugées plus performantes
L’une des innovations les plus prometteuses de la M-Competition M4 était l’utilisation d’approches d’apprentissage croisé qui permettent aux modèles d’apprendre à partir de plusieurs séries comment prédire avec précision des séries individuelles.
Dans leur article (A. Semenoglou, E. Spiliotis, S. Makridakis, V. Assimakopoulos, 2021), les auteurs ont étudié le potentiel de l’apprentissage croisé en développant divers modèles de réseaux de neurones qui adoptent une telle approche, et ils ont comparé leur précision à celui des modèles traditionnels qui sont entraînés de façon série par série.
Leur évaluation empirique, basée sur les données mensuelles M4, confirme que l’apprentissage croisé est une alternative prometteuse à la prévision traditionnelle, du moins lorsque des stratégies appropriées pour extraire des informations à partir d’ensembles de données de séries chronologiques volumineuses et diverses sont envisagées.
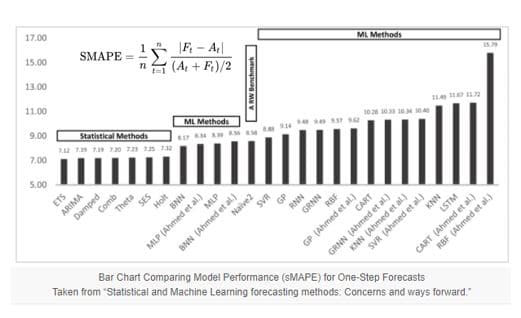
Pour plus de précision, les auteurs proposent l’utilisation de l’erreur absolue moyenne relative moyenne (AvgRelMAE), une mesure relative robuste qui suggère des améliorations de précision par rapport à la référence utilisée pour la mise à l’échelle lorsque sa valeur est inférieure à un, et vice versa.
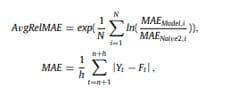
Le tableau suivant met en évidence la performance de prévision sur l’ensemble des 48 000 séries mensuelles et 18 horizons de prévision des différents modèles considérés dans cette étude, ainsi que celle des benchmarks sélectionnés. La complexité du modèle (MC) fait référence au nombre de paramètres pouvant être entraînés et le temps de calcul (CT) est mesuré en minutes. OWA, l’opérateur de moyenne pondérée ordonnée (OWA) est l’une des techniques les plus utilisées dans la procédure d’agrégation de l’opérateur.