L'apprentissage Automatique est une bonne alternative pour prévoir les Produits et Services Nouveaux
L’apprentissage automatique (ou Machine Learning) peut être utilisé pour comprendre et prédire le lancement d’un nouveau produit avec des attributs particuliers. Mais la précision de la prévision pour un nouveau produit donné dépendra fortement de la qualité des attributs spécifiés et retenus dont le nouveau produit pourrait s’en rapprocher.
Il est important de noter que, plus les produits utilisés pour former le modèle ML au nouveau produit sont similaires, mieux la technique fonctionnera.
Qu'est ce que le Machine Learning ?
Selon SAP, « l’apprentissage automatique est un sous-ensemble de l’intelligence artificielle (IA). Il vise à apprendre aux ordinateurs à assimiler des données et à s’améliorer avec l’expérience – au lieu d’être explicitement programmés pour le faire. Dans l’apprentissage automatique, les algorithmes sont formés pour trouver des modèles et des corrélations dans de grands ensembles de données et pour prendre les meilleures décisions et prédictions sur la base de cette analyse.
Les applications d’apprentissage automatique s’améliorent avec l’utilisation et deviennent plus précises à mesure qu’elles ont accès à davantage de données. »
Prévoir avec le Machine Learning ?
Les techniques d’apprentissage automatique et les algorithmes permettent de prédire la quantité de produits et de services à acheter au cours d’une période future définie. Dans ce cas, un système logiciel peut apprendre des données pour une meilleure analyse. Par rapport aux méthodes traditionnelles de prévision de la demande, une approche de Machine Learning permet de :
- Accélérer la vitesse de traitement des données
- Peut fournir une prévision plus précise
- Automatisez les mises à jour des prévisions en fonction des données récentes
- Analyser plus de données
- Identifier les modèles cachés dans les données
- Créer un système robuste
- Accroître l’adaptabilité aux changements
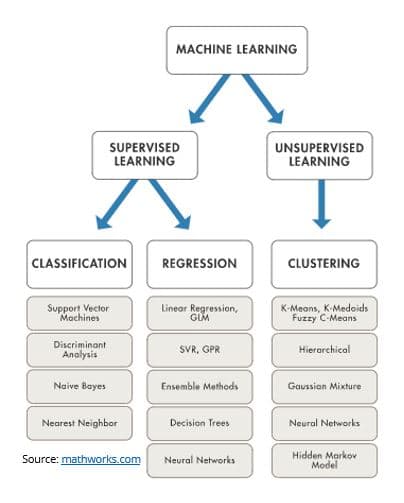
Aperçu sur les principales méthode de Machine Learning Methods
Nous pouvons utiliser l’apprentissage supervisé si nous savons à l’avance ce que nous voulons enseigner à une machine. Cela nécessite généralement d’exposer l’algorithme à un vaste ensemble de données d’apprentissage, de laisser le modèle examiner la sortie et d’ajuster les paramètres jusqu’à obtenir les résultats souhaités. Nous pouvons ensuite tester la machine en la laissant faire des prédictions pour un « ensemble de données de validation ».
Apprentissage supervisé pour la prévision de nouveaux produits :
- Si nous connaissons les groupes de similarité d’un catalogue, nous sommes en mesure d’attribuer une classe différente à chaque produit.
- On peut définir un nombre arbitraire de classes, mais chacune d’entre elles doit être largement représentée par un nombre adéquat de produits.
- Une fois les classes définies, nous devons représenter un produit avec une description d’article. Nous pouvons ajouter un nombre arbitraire d’attributs pertinents : matières premières, couleurs, tailles et autres.
- Les méthodes d’apprentissage automatique supervisées formeront un classificateur capable de mapper chaque produit à la classe
associée via la description de l’article. - Par conséquent, étant donné un nouveau produit, nous devons le décrire, puis le modèle d’apprentissage automatique formé lui attribue la
classe la plus appropriée. - Une fois trouvé l’ensemble des produits similaires, nous pouvons faire la prévision des nouveaux produits de plusieurs manières
Apprentissage non supervisé pour la prévision de nouveaux produits:
L‘apprentissage non supervisé permet à une machine d’explorer un ensemble de données. Après l’exploration initiale, la machine essaie d’identifier des modèles cachés qui relient différentes variables. Ce type d’apprentissage peut aider à transformer les données en groupes, basés uniquement sur des propriétés statistiques. L’apprentissage non supervisé ne nécessite pas de formation sur de grands ensembles de données, et il est donc beaucoup plus rapide et plus facile à déployer, par rapport à l’apprentissage supervisé.
- Dans l’apprentissage supervisé, nous devons attribuer manuellement une classe à chaque produit du catalogue.
- Mais que se passe-t-il si le catalogue compte environ un millier de SKU* ? Cela pourrait être une opération très exigeante.
- L’apprentissage non supervisé peut le faire, une fois que les produits sont décrits avec des attributs pertinents.
- Il existe des techniques de clustering bien connues capables de regrouper tous les produits dans différents clusters en utilisant des critères de similarité entre attributs.
- Une fois les clusters calculés, il est possible de trouver des produits similaires au nouveau produit considéré.
- Une fois les produits similaires trouvés, les prévisions peuvent être exécutées.
PREDICONSULT propose une formation de Prévision des produits et services nouveaux et une en Prévision avec Machine Learning.