Comparing Forecasting Methods: “Classic” statistical Methods vs Machine Learning
Machine Learning methods are often reported to be the key solution to all predictive modeling problems and can out-perform classic methods.
Some studies have reported different comparative results. We are presenting hereafter results of two studies.
First study: Classic Statistical Methods outperform Machine Learning
In a study (Makridakis S. et al., 2018) evaluating and comparing the performance of “classic” and Machine Learning methods on a large and diverse set of more than 1,000 univariate time series forecasting datasets, and which used a series-by-series modeling strategy, we learned :
- Classic methods like ETS and ARIMA out-perform Machine Learning and Deep Learning methods for one-step forecasting on univariate datasets (based on Symmetric Mean Absolute Percentage Error).
- Classic methods like ARIMA out-perform Machine Learning and Deep Learning methods for multi-step forecasting on univariate datasets.
- Machine Learning and Deep Learning methods do not yet deliver on their promise for univariate time series forecasting and there is much work to do.
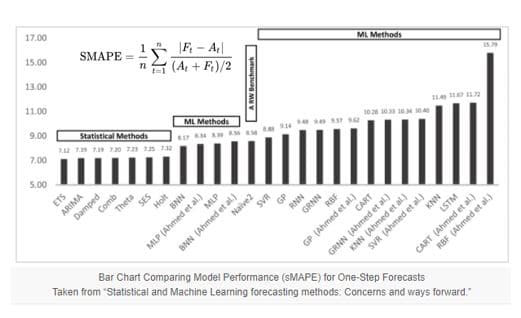
* Spyros Makridakis, et al. (2018): “Statistical and Machine Learning forecasting methods: Concerns and ways forward.”
Second study: Machine Learning Methods outperform Classic Statistical Methods
- One of the most promising innovations of M4 was the utilization of cross-learning approaches that allow models to learn from multiple series how to accurately predict individual ones.
- In their paper (A. Semenoglou, E. Spiliotis, S. Makridakis, V. Assimakopoulos, 2021), the authors investigated the potential of cross-learning by developing various neural network models that adopt such an approach, and they compared their accuracy to that of traditional models that are trained in a series-by-series fashion.
- Their empirical evaluation, which is based on the M4 monthly data, confirms that cross-learning is a promising alternative to traditional forecasting, at least when appropriate strategies for extracting information from large, diverse time series data sets are considered.
- For accuracy, the authors propose the use of the average relative mean absolute error (AvgRelMAE), a robust relative measure that suggests accuracy improvements over the benchmark used for scaling when its value is lower than one, and vice versa.
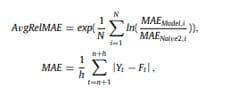
Forecasting performance across all 48,000 monthly series and 18 forecasting horizons of the various models considered in this study, along with that of the selected benchmarks. Model complexity (MC) refers to the number of trainable parameters, and computational time (CT) is measured in minutes. OWA, the ordered weighted averaging (OWA) operator is one of the most used techniques in the operator’s aggregation procedure.