
Machine Learning for Forecasting New Products
Machine Learning can be used to understand and predict a product launch for a new product with particular attributes (as defined by a training dataset), but the accuracy of the forecast for a given new product will definitely depend on how well the specified attributes actually describe or “capture” a new product.
In that regards, the more similar the products used to train the ML model to the new product, the better the technique will work.
What is Machine Learning ?
According to SAP “Machine learning is a subset of artificial intelligence (AI). It is focused on teaching computers to learn from data and to improve with experience – instead of being explicitly programmed to do so. In machine learning, algorithms are trained to find patterns and correlations in large data sets and to make the best decisions and predictions based on that analysis.
Machine learning applications improve with use and become more accurate the more data they have access to.”
Machine Learning for Forecasting
Machine Learning techniques and Algorithms allow for predicting the amount of products and services to be purchased during a defined future period. In this case, a software system can learn from data for improved analysis. Compared to traditional demand forecasting methods, a Machine Learning approach allows to:
- Accelerate data processing speed
- May provide a more accurate forecast
- Automate forecast updates based on the recent data
- Analyze more data
- Identify hidden patterns in data
- Create a robust system
- Increase adaptability to changes
Summary of Machine Learning Methods
We can use Supervised Learning if we know in advance what we want to teach a machine. This typically requires exposing the algorithm to a huge set of training data, letting the model examine the output, and adjusting the parameters until getting the desired results. We can then test the machine by letting it make predictions for a “validation data set”.
Supervised Learning for New Product Forecasting
- If we know the similarity groups of a catalog, we are able to assign a different class to each product.
- We can define an arbitrary number of classes, but each of them must be widely represented by an adequate number of products.
- Once the classes are defined, We have to represent a product with an item description. We can add an arbitrary number of relevant attributes: raw materials, colors, sizes and others.
- Supervised machine learning methods will train a classifier able to map every product to the related class through the item description.
- Hence, given a new product, We have to describe it, then the trained machine learning model assigns to it the most appropriate class.
- Once found the set of similar products, we can do the forecast of the new products in several ways
Unsupervised Learning enables a machine to explore a set of data. After the initial exploration, the machine tries to identify hidden patterns that connect different variables. This type of learning can help turn data into groups, based only on statistical properties. Unsupervised learning does not require training on large data sets, and so it is much faster and easier to deploy, compared to supervised learning.
Unsupervised Learning for New Product Forecasting
- In the supervised learning we have to manually assign a class to each product of the catalog.
- But, what if the catalog is about thousand of SKU* ? It could be a very demanding operation.
- Unsupervised learning can do it, once the products are described with relevant attributes.
- There exist well-known clustering techniques able to group all products in different clusters using similarity criteria between attributes.
- Once the clusters are computed, it is possible to find products which are similar to the considered new product.
- Once the similar products are found, then forecast could be run.
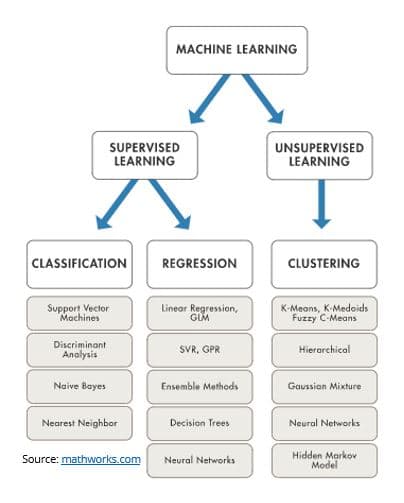
Classification and clustering algorithms , Regression methods
- Classification algorithms can explain or predict a class value. It is an essential component for many AI applications, but it is especially useful for eCommerce applications. For example, classification algorithms can help predict if a customer will purchase a product, or not. The two classes in this case are “yes” and “no”.
- Regression methods are used for training supervised ML. The goal of regression techniques is typically to explain or predict a specific numerical value while using a previous data set. For example, regression methods can take historical pricing data, and then predict the price of a similar property to retail demand forecasting.
- Clustering algorithms are unsupervised learning methods. A few common clustering algorithms are K-means, mean-shift, and expectation-maximization. They group data points according to similar or shared characteristics.